Part 2 of the Lighthouse Analytics Model, this post covers the Key Functions of the Data Analytics CoE. This is a rather short summary post, no need to spell out the details , rather highlight the key functions.
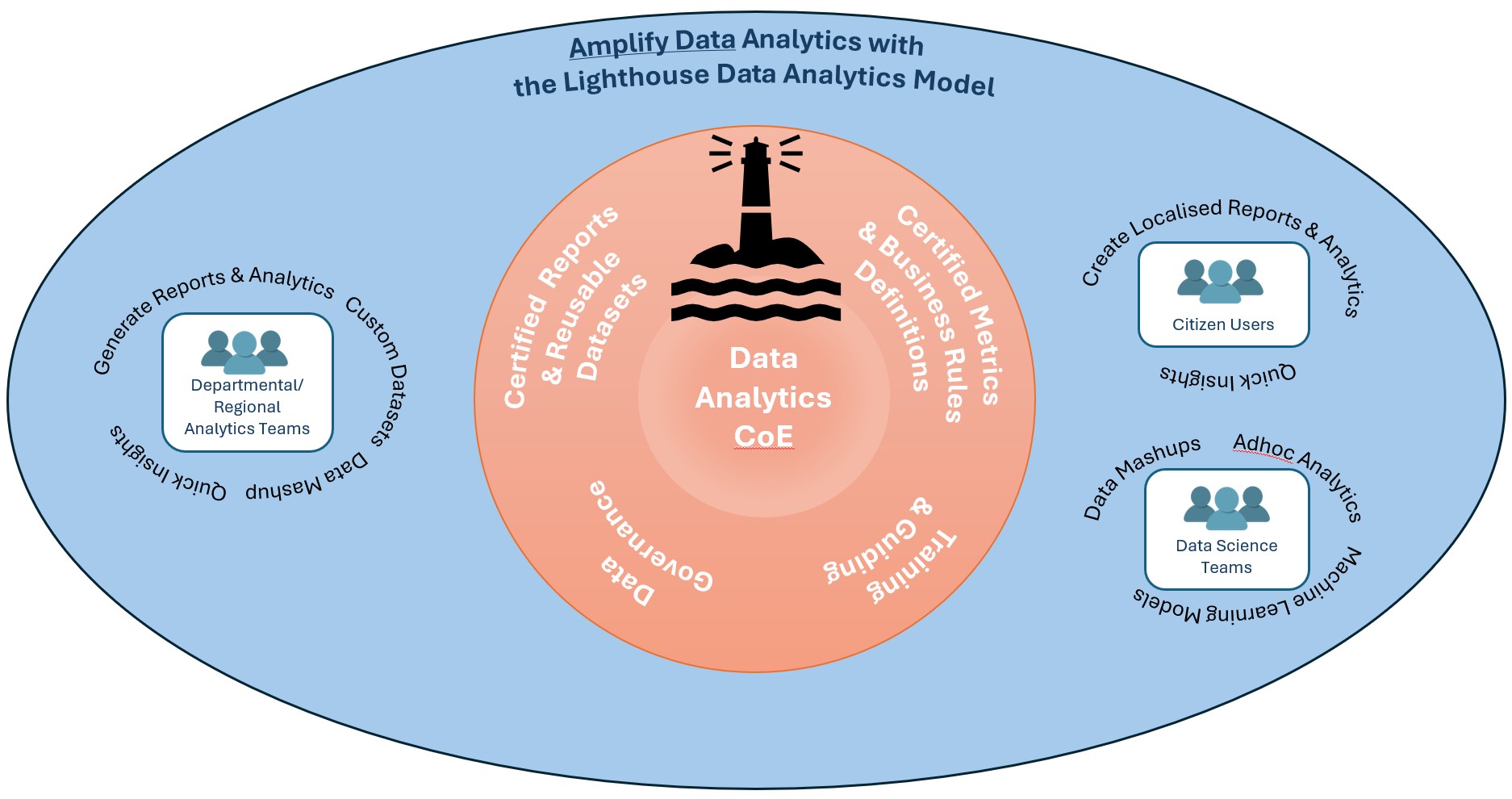
The Data Analytics CoE plays a pivotal role in organisations for Amplifying Data Analytics. It sets the path and guard rails on how departments & users can/should interact with Data for Data Analytics purposes.
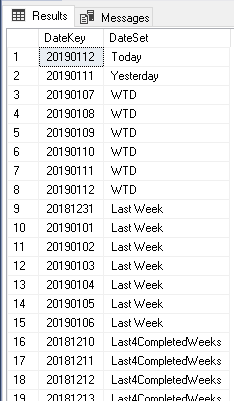
Data Analytics CoE Key Functions
| Key Functions | Info |
| Certified Metrics | Produce key certified metrics for reuse-ability. These metrics are trusted by the organisation for accuracy and validity |
| Business Rules and Definitions | Organisation wide – clear, concise and consistent Business definitions and rules. Resulting in reduced confusion and increased alignment. |
| Certified Reports/Dashboards | Pre-built Reports & Dashboards usable by authorized users / departments. These provide the trusted data on key subject areas. It may not address all business questions however is geared towards providing access to the majority of key metrics. |
| Certified Reusable Datasets | Host Foundational Datasets usable by all departments. These are key for all complex and ad-hoc data analytics. Power Users can reuse and further enrich these in their own workspaces. End users utilise these for the majority of their ad-hoc analytics. These can be in the form of Databases and/or cubes. AI/ML initiatives will also rely heavily on these certified datasets. |
| Data Governance | Governance scope is analytics assets only and not enterprise wide. The policies, processes and practices established to ensure that data used for analytics is accurate, secure, and compliant with regulations. CoE would put these in place and audit them with an optional step of enforcement (if not handled by other departments). Guard rails are established as part of governance to enable users flexibility but also restrictions on what they can or cannot do. |
| Training and Guidance | Data Literacy is the key for amplifying analytics in organisations. Data Literacy requires ongoing training and guidance on what data is available but more importantly how to use and interact with data to answer business questions. Training programs are essential in building power users in the organisation who in turn will empower other users and increase the data literacy of the organisation. Guidance refers to raising awareness of users responsibilities and how to work with data – this is a mix of training and governance. |
The above are the core functions of what the Data Analytics CoE would perform in the Lighthouse Analytics Model, and hoping the above will aid in achieving the amplification of data analytics in the organisation.
Not going into much detail as most of these functions can be expanded easily by data experts, the objective of this post is to identify the key functions and its objectives .
Part 1 Amplify Data Analytics – Decentralise and embed into the business